













「Media2Face」は、リアルタイムで表情豊かなAIアバターを生成する新技術です。従来の3Dアニメーションの限界を突破し、音声やテキストからリアルな表情を生み出します。この記事ではMedia2Faceの革新性とその応用を解説します。
ビジネスとAIの最新情報は当サイトで毎日更新中です。ぜひブックマークをお願いします。
Media2Faceとは?
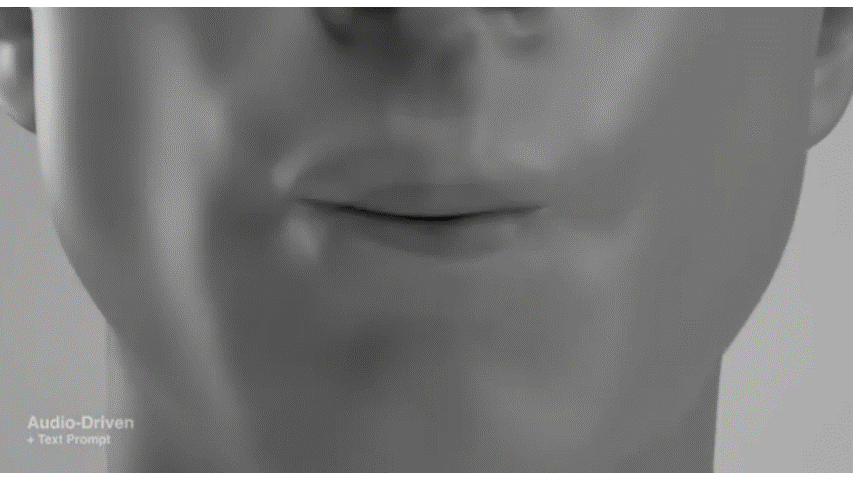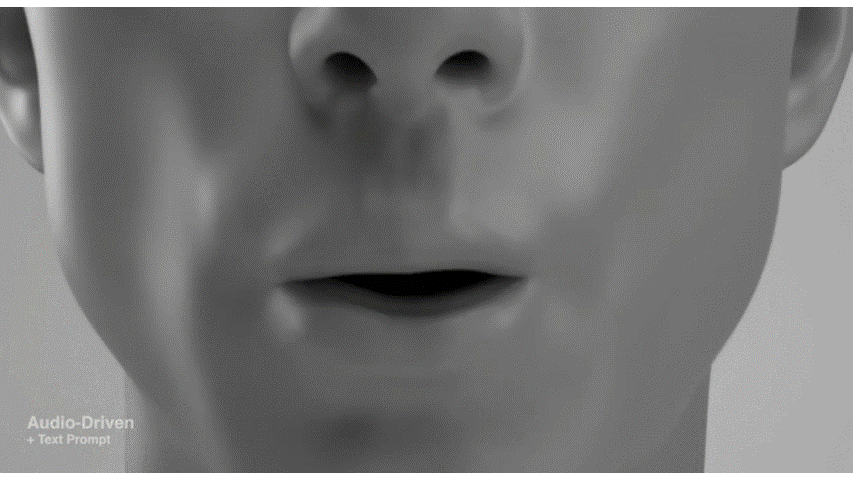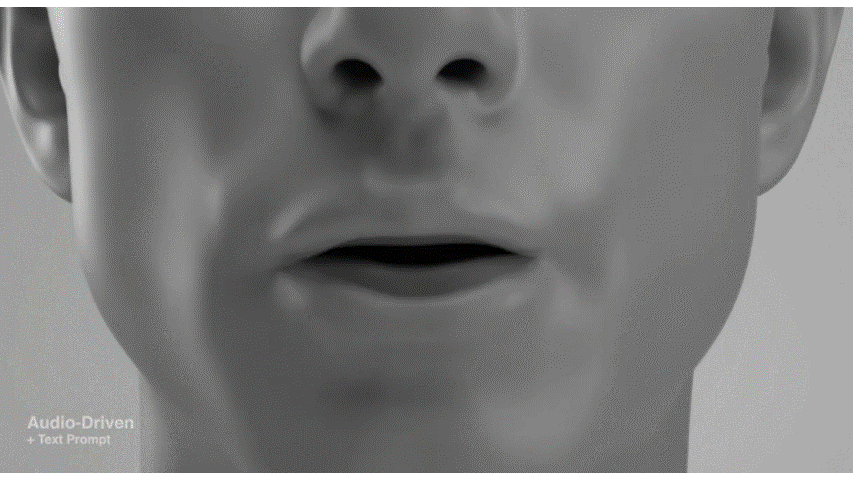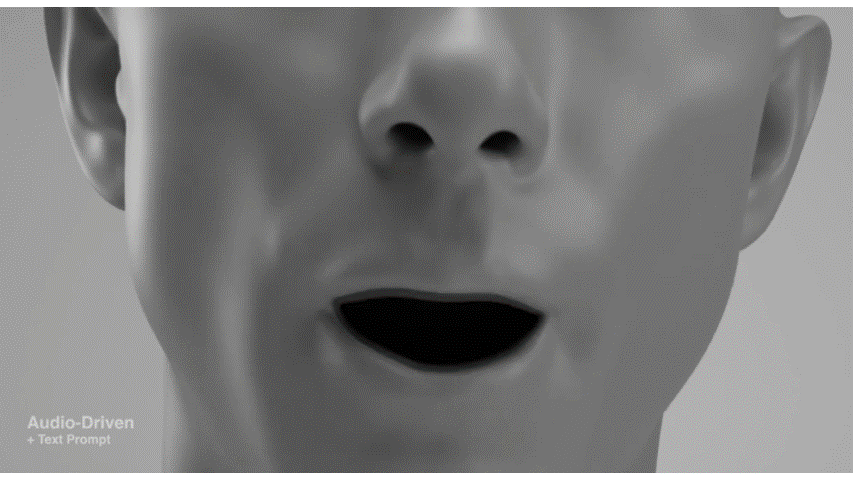
Media2Faceは、音声入力から3D顔アニメーションを合成する方法です。音声、テキスト、画像入力に基づいて、リアルで表現豊かな顔アニメーションを生成する能力が特に注目されています。
参照:Media2Face
Media2Faceの何が新しいのか?
- マルチモーダリティガイダンス
- 高品質データセット (M2F-D)
- 一般化ニューラルパラメトリック顔資産 (GNPFA)
- 拡散モデル
マルチモーダリティガイダンス
以前の方法とは異なり、Media2Faceは音声、テキスト、画像からの複数のソースを統合することができます。
高品質データセット (M2F-D)
多くのビデオから高品質な表現と正確な頭部のポーズを抽出します。
一般化ニューラルパラメトリック顔資産 (GNPFA)
これは表現と身元を切り離し、顔のジオメトリと画像を一般化された表現の潜在空間にマッピングする変分オートエンコーダーです。
拡散モデル
GNPFA潜在空間で使用され、生成された顔アニメーションの忠実度と表現力を高めます。
Media2Faceの開発と運営
上海科技大学のQingcheng ZhaoとPengyu Longをリーダーとするチームが、Deemos Technology、香港大学、DGene Digital Technology Co., Ltd.と共同で開発しました。
チーム構成: プロジェクトはQixuan Zhangによって主導され、これらの機関の複数の研究者から重要な貢献がありました。
Media2Faceの主な機能

- ジオメトリVAE
- ビジョンエンコーダー
- 複数の入力に対する条件付け
- 顔アニメーションの生成
ジオメトリVAE
表現と頭部のポーズの潜在空間を学ぶ変分オートエンコーダーで、表現を身元と分離します。
ビジョンエンコーダー
RGB画像から表現潜在コードと頭部ポーズを抽出するために訓練され、幅広い4Dデータを捉えます。
複数の入力に対する条件付け
モデルはオーディオ特徴とCLIP潜在コードを条件として取り、より多様で表現力のあるアニメーションを可能にします。
顔アニメーションの生成
システムは表現ジオメトリとモデルテンプレートを組み合わせ、頭部のポーズパラメータによって強化された最終的な顔アニメーションを生成します。
応用事例

対話シーンの生成
モデルは、脚本化されたテキスト記述を使用して鮮明な対話シーンを生成できます。
スタイリッシュな顔アニメーション
絵文字やさらに抽象的な画像を含む画像プロンプトを通じて、スタイリッシュな顔アニメーションを合成できます。
まとめ
「Media2Face」の可能性は、今後のAI技術とビジネスの世界において大きな影響を与えることでしょう。リアルタイムで表情豊かなアバターを生み出すこの技術が開く新たな扉は、想像以上のものです。最新のAI技術とそのビジネスへの応用に関する情報をこれからもお届けしますので、ぜひ引き続き当サイトをご覧ください。次回の記事もお見逃しなく!

コメント