













AI画像を生成する時、決まった人物で様々なパターンを作りたいことはありませんか?
UNIMO-Gは被写体にタグをつけて、様々なタイプやシーンに投影し画像生成をしてくれます。シチュエーションの変換だけでなく、服などの着せ替えも実現させます。
本記事ではUNIMO-Gの概要や機能、モデルバージョン、活用事例などを分かりやすく解説します。
本記事では毎日ビジネスに関するAI情報を配信しております。ぜひ、ブックマークをしてお見逃し無いようにお願いいたします。
UNIMO-Gとは?

UNIMO-Gは、テキストと画像の入力を組み合わせた多様なプロンプトに基づいて画像を生成する新しいAIモデルです。
UNIMO-Gの何が新しい?
今までは、テキストのみの説明では詳細な画像を生成するのが難しいこともあったと思います。UNIMO-Gはテキストと視覚的入力を交互に使うことで、より複雑で詳細な画像を作り出すことができます。
参照:UNIMO-G: Unified Image Generation through Multimodal Conditional Diffusion
UNIMO-Gの特徴
- 多様なモードの大規模言語モデル(MLLM)
- 条件付きノイズ除去拡散ネットワーク
- 二段階のトレーニング戦略
- データ処理パイプライン
- T2I&ゼロショット主題駆動合成
UNIMO-Gの主要な特徴を解説します。
多様なモードの大規模言語モデル(MLLM)
マルチモーダルプロンプトを符号化するためのコンポーネントです。
条件付きノイズ除去拡散ネットワーク
符号化されたマルチモーダル入力に基づいて画像を生成するためのコンポーネントです。
二段階のトレーニング戦略
大規模なテキスト-画像ペアでの事前学習を行い、その後マルチモーダルプロンプトを使用した指示チューニングを行います。これにより、統合された画像生成能力を獲得します。
データ処理パイプライン
言語の基礎づけと画像のセグメンテーションを含む、マルチモーダルプロンプトを構築するためのデータ処理パイプラインが設計されています。
T2I&ゼロショット主題駆動合成
UNIMO-Gは、テキストから画像への生成とゼロショット主題駆動合成の両方で優れた性能を発揮します。特に、複数の画像エンティティを含む複雑なマルチモーダルプロンプトから高忠実度の画像を生成するのに効果的です。
UNIMO-Gの開発元は?
UNIMOはBaiduが開発を主導しています。将来的にはBaiduのSNSサービスに実装されるのかもしれません。
UNIMO-Gの機能は?〜何ができる?~
T2I(Text to Image)

まずはプロンプトから画像生成ができます。この機能は従来の生成画像AIサービスと大差ありません。
Multimodal to Image Generation

そして、これがUNIMOの真骨頂です。画像編集をAIがやることは従来のサービスでもありました。しかし、上記例では元画像の人物がしっかりと保持された上でエフェクトがかけられていることがわかります。
UNIMOのモデルバージョン
- UNIMO-G
- UNIMO-2
- UNIMO-1
UNIMO-G
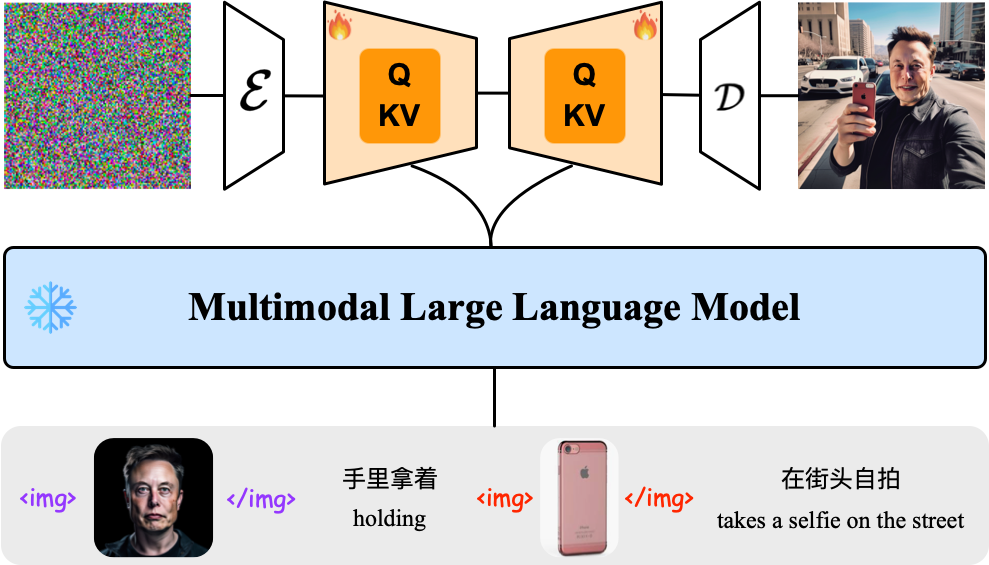
テキストと画像の両方を入力として使う多モーダル条件付き拡散フレームワークです。UNIMO-Gは、テキスト駆動型と主題駆動型の画像生成の両方において優れた能力を持っています。
このモデルは、多様なモードの大規模言語モデル(MLLM)と条件付きノイズ除去拡散ネットワークを使って、複雑なマルチモーダルプロンプトから高忠実度の画像を生成します。
UNIMO-2
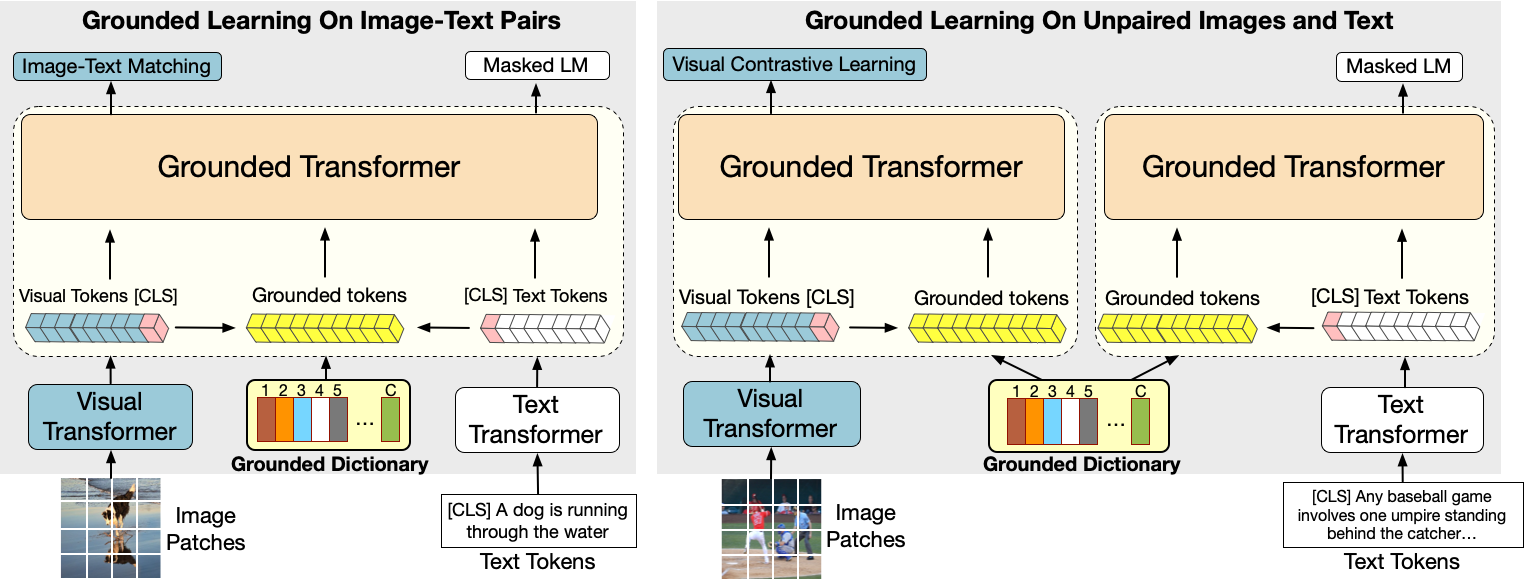
統一されたモーダル事前学習フレームワークで、画像・キャプションのデータだけでなく、画像のみやテキストのみのデータも含む、より広範囲な学習を行います。
UNIMO-2は、画像とテキスト間の意味的整合性を改善するために、「共有された基礎空間」を通じて画像とテキストの両方に焦点を当てた学習を行います。
UNIMO-1
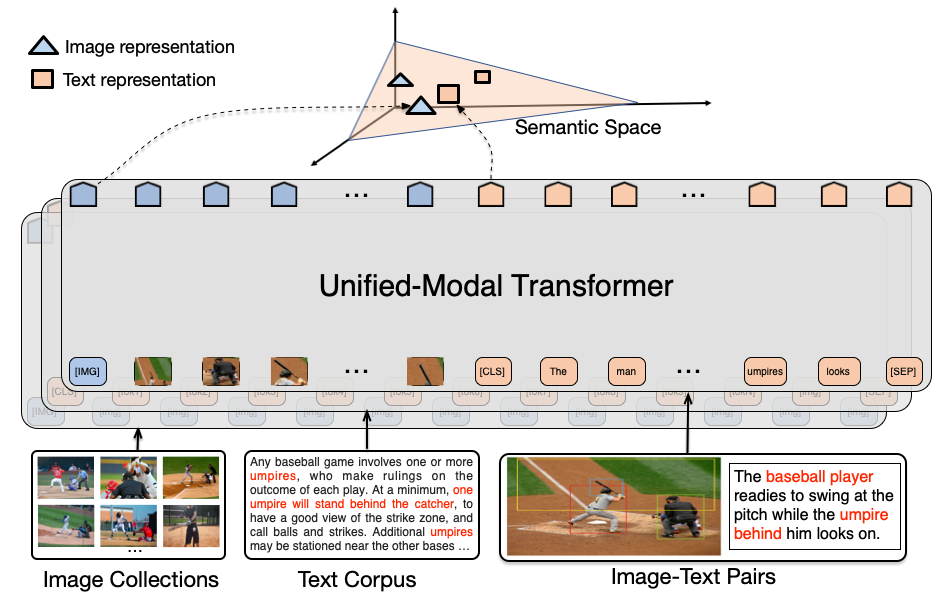
単一モーダル(テキストまたは画像のみ)とマルチモーダル(画像-テキストペア)のタスクの両方に適応できる統一モーダル事前学習アーキテクチャです。
UNIMO-1は、クロスモーダルコントラスト学習を使用して、テキストと視覚情報を統合的な意味空間に整合させます。
UNIMO-Gとアプリケーションやサービスに統合
- コンテンツ制作とデザイン
- 教育とトレーニング
- 仮想現実(VR)と拡張現実(AR)
- ソーシャルメディアとエンターテイメント
- コンテンツのパーソナライゼーション
- 研究と開発
UNIMO-Gは、その高度な画像生成能力とマルチモーダルプロンプトの処理能力を活かして、様々なアプリケーションやサービスに統合することができます。
コンテンツ制作とデザイン
UNIMO-Gは、広告、映画、ゲーム、出版物などでビジュアルコンテンツを生成するために使用できます。特に、複雑なシナリオや抽象的なアイデアをビジュアル化する際に有用です。
教育とトレーニング
教育的な資料やトレーニングプログラムにおいて、テキストベースの説明を補完するビジュアルエイドとしてUNIMO-Gを活用できます。これは、特に複雑な概念やプロセスを視覚的に理解するのに役立ちます。
仮想現実(VR)と拡張現実(AR)
UNIMO-Gは、リアルタイムでのVRやAR環境のためのカスタマイズ可能なビジュアルコンテンツの生成に使用できます。これにより、より没入型でリアリスティックな体験が可能になります。
ソーシャルメディアとエンターテイメント
ソーシャルメディアプラットフォームやエンターテイメントアプリで、ユーザーが独自の画像やアートワークを作成するためのツールとして統合できます。
コンテンツのパーソナライゼーション
ユーザーの好みや過去の行動に基づいて、パーソナライズされたビジュアルコンテンツを生成するために、eコマース、ニュースサイト、またはパーソナライズされた広告に活用できます。
研究と開発
学術研究や産業設計において、概念のビジュアル化やプロトタイピングにUNIMO-Gを利用できます。
まとめ
UNIMO-GはBaiduの技術ということで、日本人には直接関わりのない技術なのかもしれません。しかし、研究開発段階で日本のAIエンスージアシストやビジネスアーリーバードの方々には面白い情報となるのではないでしょうか?
本記事が皆様のビジネスにお役に立てる情報となれば幸いです。
本サイトでは日々のビジネスシーンに役立つAI関連の最新情報をお届けしています。ぜひブックマークをして、重要な更新を見逃さないようご注意ください。毎日のビジネス生活に役立つ情報をお届けすることをお約束します。


コメント