



話題のダンス系ショート動画、顔写真だけで作れるとしたら?
今回はAlibabaが開発するAI技術「DreaMoving」についてレポートいたします。
AI分野の記事制作はぜひ、ひとり構造改革編集部にお任せください。定期納品で時事トレンドを活かしたSEOで、メディア様・企業様のコンテンツ戦略に貢献させていただきます。
AlibabaのDreaMovingとは?

Alibabaが開発するAI生成システムです。必要なのは顔写真だけです。あとは、AIが身体や動作、背景などから適切なものを生成してくれます。
AnimateAnyoneやMagicAnimateとの違いは?

AnimateAnyoneは同じくAlibabaが開発するモーション生成AIです。静止画像からダンスなどの動画を生成します。また、キャラクター変更もできます。
MagicAnimateはByteDanceが開発するモーション生成AIです。AnimateAnyoneと違うところは動画からもエフェクトをAIが加えられるところです。
AnimateAnyoneやMagicAnimateは全身画像、もしくは動画をトラッキングする必要がありますが、DreaMovingに必要なのは顔写真1つだけです。
関連記事:Animate Anyoneとは?人物画像を動かすAIの始め方/使い方
関連記事:MagicAnimateとは?ByteDance×3DアニメーションでSNS戦略を効率化
DreaMovingの仕組みは?

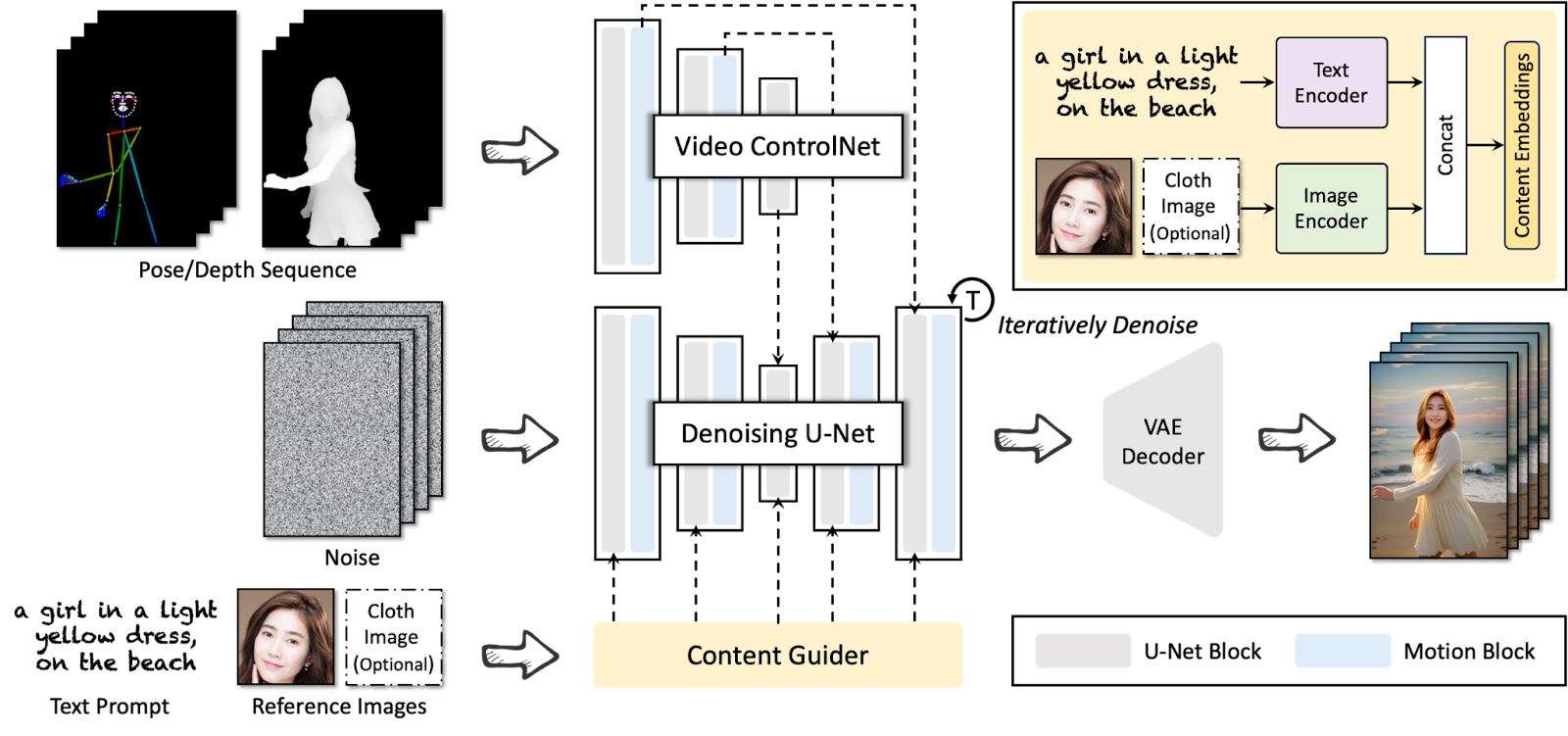
- エンコーダー
- ポーズ/深度シーケンス
- ノイズ
- ビデオコントロールネット
- デノイジング U-Net
- VAEデコーダー
- 完成
テキストプロンプトと参照画像
ユーザーは「a girl in a light yellow dress, on the beach」というテキストプロンプトを提供し、場合によっては衣服の画像などの参照画像をオプショナルで提供します。
エンコーダー
提供されたテキストと画像はそれぞれテキストエンコーダーと画像エンコーダーを通して処理されます。これにより、テキストと画像の情報が組み合わされて、コンテンツガイダンスが生成されます。
ポーズ/深度シーケンス
人物のポーズやシーンの深度に関する情報が準備されます。
ノイズ
初期の「ノイズ」画像が作成され、これは生成プロセスの出発点となります。
ビデオコントロールネット
ポーズや深度のシーケンスと初期ノイズから、ビデオのフレームを制御するための情報が生成されます。
デノイジング U-Net
ノイズの多い画像シーケンスを反復的に洗練させていく過程で、デノイジングU-Netが使用されます。このステップで、画像からノイズを取り除き、よりクリアな画像を生成します。
VAEデコーダー
デノイジングされた画像データは、VAE(変分オートエンコーダー)デコーダーを使用して最終的な画像に変換されます。
完成
プロセスの最終ステップとして、テキストプロンプトに基づいて生成された、砂浜にいる黄色いドレスを着た女性の画像が出力されます。
DreaMovingで何ができる?
まだまだ実装、もしくは統合されるアプリが決定していないので詳細の機能は不明ですが、2023年12月時点でSNSで使用できるようなショート動画くらいの品質は追求できそうです。中華系アプリへの統合がされるのでしょうか。
全身画像のエフェクト

顔写真から全身画像のエフェクトをAIで生成できます。
背景のエフェクト

背景も変えられます。
キャラクターのアニメーションにも

動きをインプットすることでキャラクターのアニメーション生成にも使用できます。
まとめ
I2V分野がかなり盛り上がってきています。SNS、特にショート動画制作で使用している方が増えてきている印象があります。DreaMovingであれば、自分を盛った顔写真だけで動画生成は完了できるので簡単ですね。
以上、AlibabaのDreaMovingについて解説させていただきました。AIテーマの記事制作は時事レスポンスが重要です。タイトル構成案ともに全て一括で定期納品いたします。ぜひ、お気軽にご連絡ください。